Dev Diary - First look at a source-to-staging pattern in Mapping Data Flows
September 19, 2021
The 2021 BimlFlex release is being finalized, and will be available soon. This release contains a preview version of Mapping Data Flow patterns that can be used to generate this type of output from BimlFlex. The corresponding (and updated) BimlStudio will of course have the support for the full Mapping Data Flow Biml syntax.
The first pattern you will be likely to see is the loading of a data delta from a source into a Staging Area and an optional Persistent Staging Area (PSA). Whether a PSA is added is controlled by adding a PSA connection to the project that sources the data. So, adding a PSA connection will add a PSA to the process, unless overridden elsewhere.
Conceptually, the loading of data into a Staging Area and PSA are two separate data logistics processes. For Mapping Data Flows, these are combined into a single data flow object to limit the overhead and cost involved with starting up, and powering down, the Integration Runtime. Data is loaded once and then written multiple times from the same data flow. This approach is something we'll see in the Data Vault implementation as well.
This means that a source-to-staging loading process has one source, and one or two targets depending if the PSA is enabled. BimlFlex will combine these steps into a single Mapping Data Flow that looks like this:
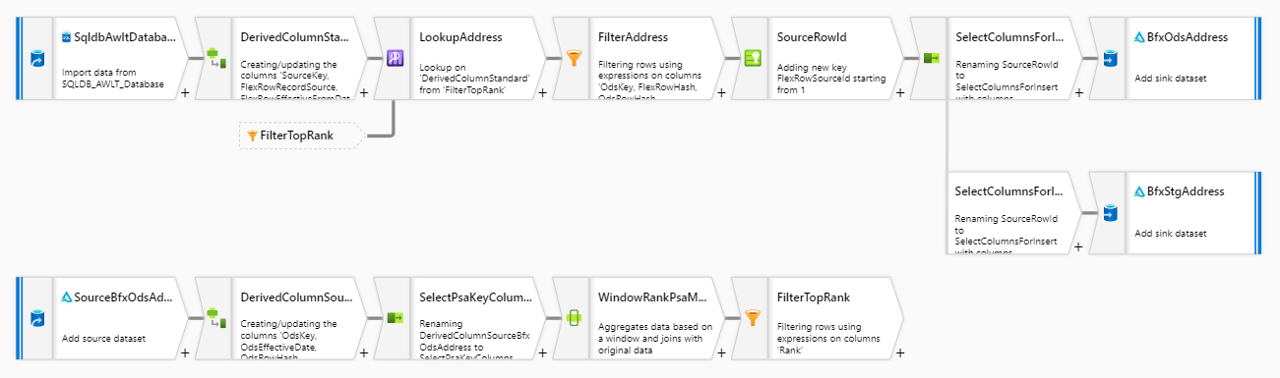
This is by no means the only way to load data from a data source into the solution. Especially this layer requires various ways to load the data, simply because it can not always be controlled how the data is accessed or received. Potentially many limitations in applications, technology, process and organization apply - and this drives the need for different patterns to cater for different systems and / or scenarios. The staging layer is often the least homogenous in terms of approach for the data solution, and the full BimlFlex solution will see a variety of different patterns driven by settings and configurations.
If we consider this particular pattern, we can see that the PSA is used to check if data is already received. If no PSA is available, the data is just copied from the source into the (Delta Lake) Staging Area.
The validation whether data is already available is done using a Lookup transformation. The lookup compares the incoming record (key) against the most recent record in the PSA. If the incoming key does not exist yet, or it does exist but the checksums are different, then the record is loaded as data delta into the Staging Area and also committed to the PSA. 'Most recent' in this context is the order of arrival of data in the PSA.
At the moment the supported sources and targets for this process are Azure SQL databases and Delta Lake, but the Biml language now supports all connections that are provided by Azure Data Factory and Mapping Data Flows so more will be added over time.
However, using Delta Lake as an inline dataset introduces an interesting twist in that no SQL can be executed against the connection. This means that all logic has to be implemented as transformations inside the data flow. For now, the patterns are created with this in mind although this may change over time.
The most conspicuous consequence of this requirement is that the selection of the most recent PSA record is implemented using a combination of a Window Function and Filter transformation. The Window Function will perform a rank, and the Filter only allows the top rank (most recent) to continue.
Over the next few weeks we'll look into more of these patterns, why they work the way they do and how this is implemented using Biml and BimlFlex.