Dev Diary - Configuring load windows and filters for Mapping Data Flows
February 10, 2022
When developing a data solution, it is often a requirement to be able to select data differentials ('deltas') when receiving data from the operational systems that act as the data 'source'.
This way, not all data is loaded every time a given source object (table, or file etc.) is processed. Instead, data can be selected from a certain pointer, or value, onwards. The highest value that is identified in the resulting data set selection can be maintained in the data logistics control framework. It is saved in the repository, so that the next time the data logistics process starts, the data can be selected from this value onwards again.
This is sometimes referred to as a high water mark for data selection. Every time a new data differential is loaded based on the previously known high water mark, a new (higher) water mark is recorded. This assumes there is any data available for the selection, otherwise the high water mark remains as it was. The process is up-to-date in this case. There is nothing to do until new data changes arrive.
The range between the most recent high water mark and the highest value of the incoming data set can be referred to as the load window. The load window, as combination of a from- and to value, is used to filter the source data set.
To implement this mechanism, the data logistics process first retrieves the most recent high water mark from the repository (the 'from' value). Then, the data source is queried to retrieve the current highest possible value (the 'to' value). The 'from' and 'to' values define the load window, and are added to the selection logic that connects to the data source.
If the 'from' and 'to' values are the same, there is no new data to process. The selection can be skipped. In this scenario, there also is no need to update the high water mark for the next run. If the data retrieval was to be executed, it would not return data anyway.
When the 'to' value is different, this is updated in the repository.
Configuring load windows in BimlFlex
In BimlFlex, this mechanism can be implemented using parameters. Parameters are essentially filters that can be used to limit the data selection for the object that they apply to.
A parameter can have a 'from' and a 'to' component, or only a 'from' one. If both a specified, BimlFlex will treat this as a load window. If only the 'from' part is specified it will be treated as a filter condition.
In the example below, the Salesforce 'Account' object has a parameter defined for the 'LastModifiedDate' column. The 'from' name of this value is 'Lastmodified', and the 'to' name is 'Nextmodified'.

Because Salesforce is an unsupported data source in Mapping Data Flows ('data flows'), the data logistics that is generated from this design metadata will include a Copy Activity to first 'land' the data. Because this is the earliest opportunity to apply the load window filter, this is done here. Driven by the parameter configuration, the query that will retrieve the data will include a WHERE predicate.
In addition, BimlFlex will generate 'lookup' procedures that retrieve, and set, the high water mark value using the naming specified in the parameter.
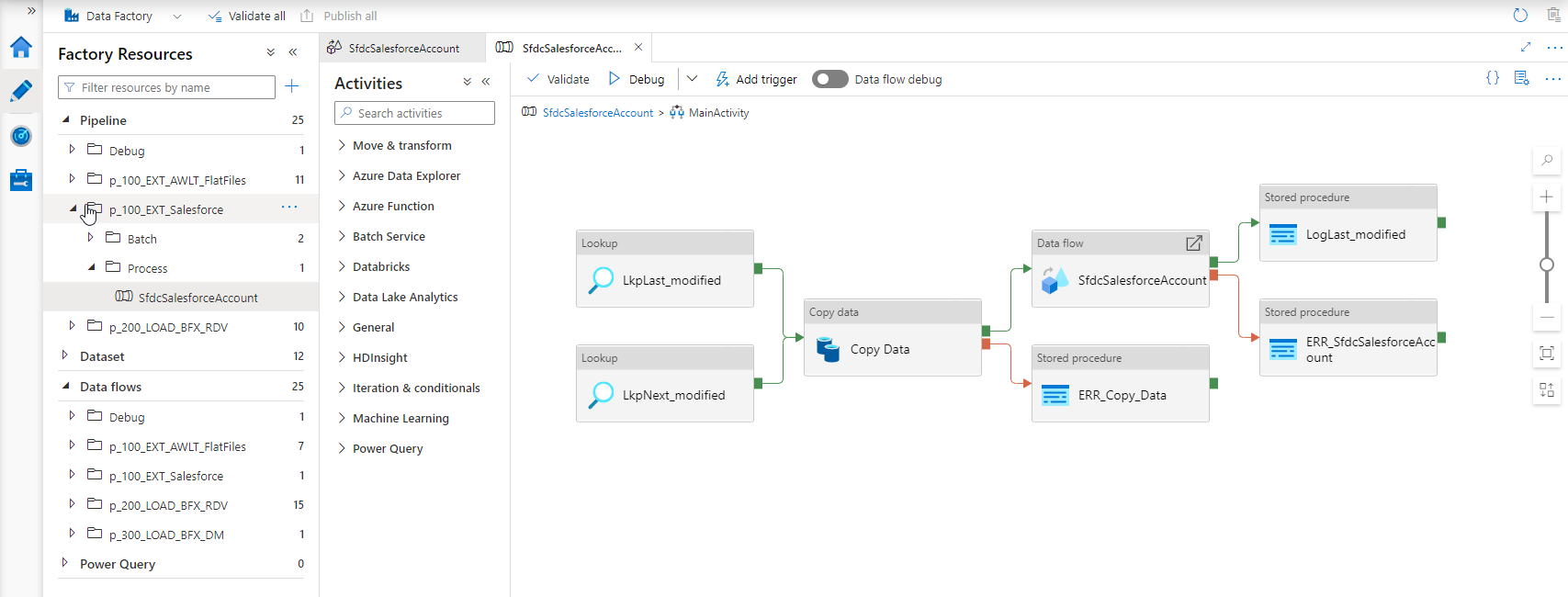
Direct filtering in Mapping Data Flows
In regular loading processes, where the data flow can directly connect to the data source, the Copy Activity is not generated. In this case, the filtering is applied as early as possible in the data flow process. When this can be done depends on the involved technologies.
For example, using a database source it is possible to apply this to the SQL SELECT statement. When using inline processing for Delta Lake or file-based sources this is done using a Filter activity.
For example, as displayed in this screenshot:
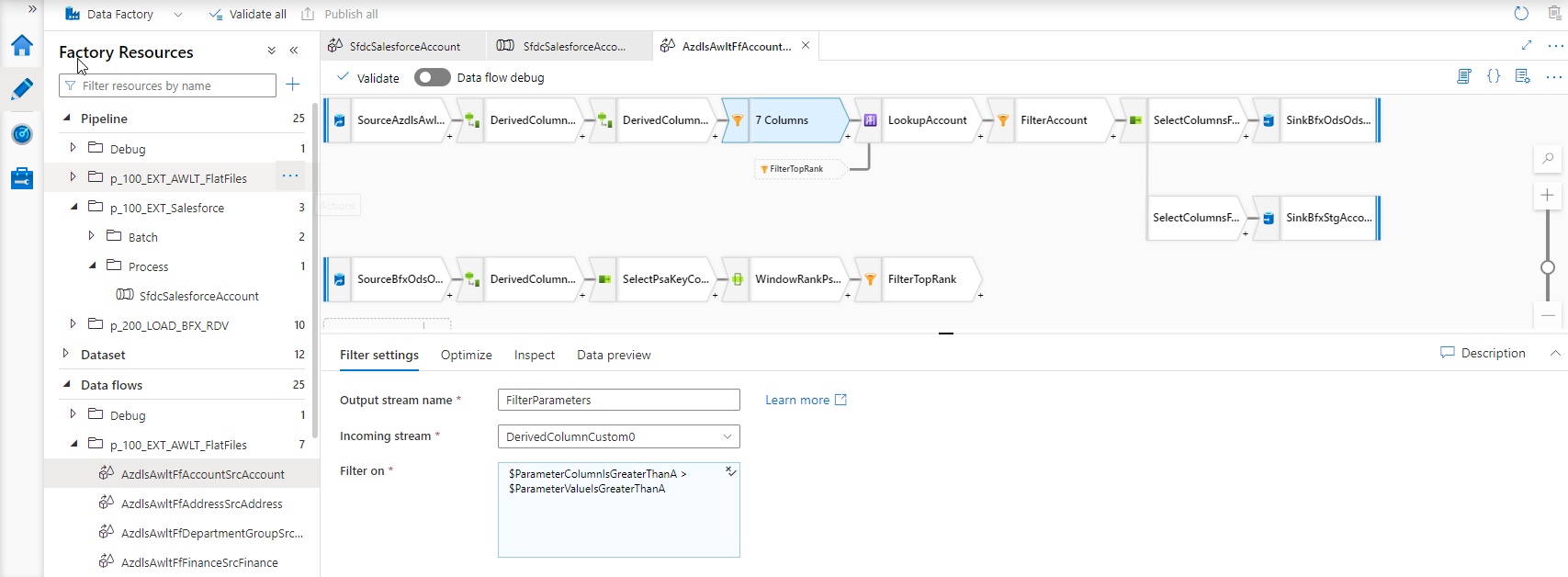
True to the concepts outlined in earlier blog posts, the BimlFlex parameters are themselves defined as Mapping Data Flow parameters to allow for maximum flexibility. The executing ADF pipeline will provide these to the data flow. The parameter values are passed down into the data flow.
Next steps
At the time of writing, database sources have not been optimized to push the selection to the data source as a WHERE clause. So, the SELECT statement is not yet created for database sources to accommodate filtering here - which is conceptually the most performant outcome. However, the filtering as per the above screenshot already works so, functionally, the output is the same.
It is equally possible to now define load windows on file-based data sources, and this is also an area to investigate further. Using data flows, the BimlFlex parameter concept for generating load windows is not restricted to database sources any longer.