Introduction to Databricks Solutions with BimlFlex Data Automation
October 18, 2023
In the ever-evolving landscape of data integration and analytics, the fusion of Databricks and BimlFlex offers a game-changing approach. Here's a comprehensive look into their integration and how this combo can enhance your Azure Data Factory operations.
Setting the Stage with Databricks
To tap into the power of Databricks:
- Establish Your Connections: Start with connecting your data sources. Be it SQL Server data, flat files, JSON, REST API, or even FTP/SFTP systems - everything can be integrated. Notably, parquet files also play a pivotal role.
- Create a Landing Connection: This is your gateway to ensure that the data you import is first stored in a data lake and subsequently in a persistent data lake. It ensures that original files are preserved.
- Transition to Staging Environment: This is achieved via an ODBC connection. It acts as an integration placeholder and facilitates metadata import from Databricks.
- Compute Connection: This is a flexible feature, allowing for multiple compute clusters if required. In our demonstration, it's configured for Azure Data Factory.
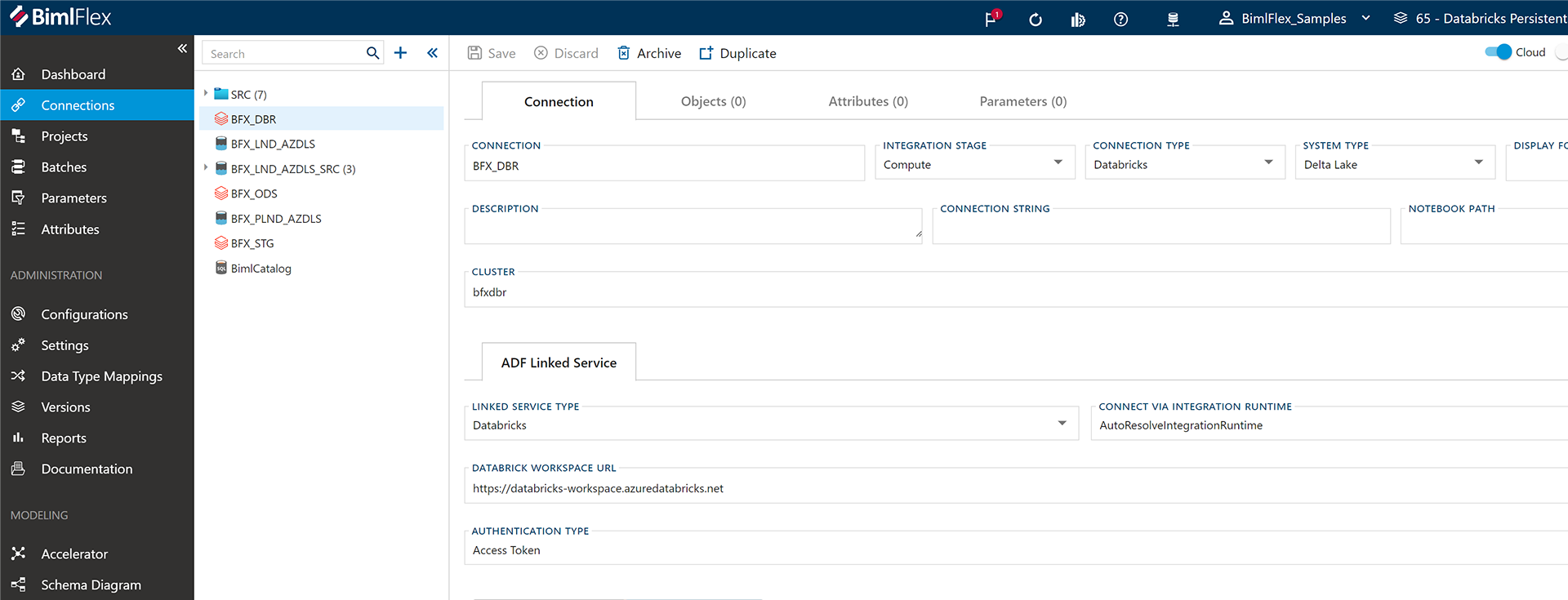
Configuring Data Load and Management
The project site is where you can dictate the data loading process:
- Extraction: Data is pulled from the source connection.
- Landing & Persistence: Data is saved as parquet files in a data lake and retained for future use.
- Staging: The retained data is staged using a Databricks compute cluster.
Furthermore, within Databricks settings, users have a plethora of configurations available, including Unity Catalog, Manage Tables, Global Parameters, and Temporary Views. These offer customizability, especially concerning time zones and other specificities.
Integrating with Azure Data Factory
Once your Databricks project is set up, it will automatically generate all the necessary Databricks notebooks and Azure Data Factory pipelines. Here are the steps:
- Optimized Azure Data Factory Pipelines: With a two-step process of a high watermark lookup followed by a copy process, data extraction becomes efficient, eliminating redundant operations.
- Data Vault Management: This feature manages the staging process for both source and persistent staging. If activated, it also initiates the Data Vault notebook.
- Archiving Data: Users have the flexibility to archive extracted files. Once archived, the initial files in the staging area are removed for optimized storage management.
All these settings are easily toggled, making global parameters a significant asset in the process.
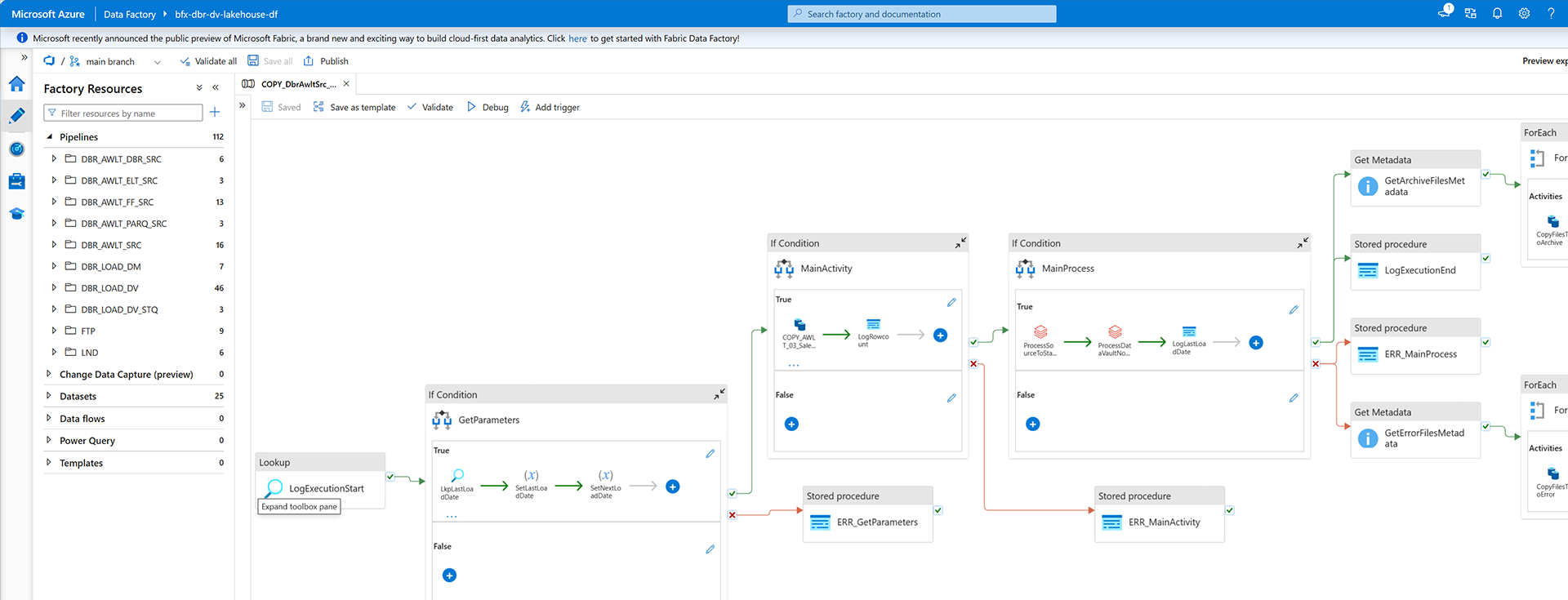
Delving Deeper into Azure Data Factory Pipelines
The integration shines when we look at how Azure Data Factory pipelines operate in tandem with Databricks. All pipeline artifacts are saved in a repository, like a GitHub repository, allowing streamlined development operations.
When you navigate to the Azure Data Factory instance and access the Repositories section, it's easy to find all associated files and artifacts. Notably, the table scripts, housed in a dedicated folder, are the backbone of the operation. These scripts, mostly in Python, deploy the pipelines with each having its unique operational instructions.
Moreover, the integration provides a customized data loading mechanism. With the persistent staging feature, the scripts decide if a full or delta process is needed.
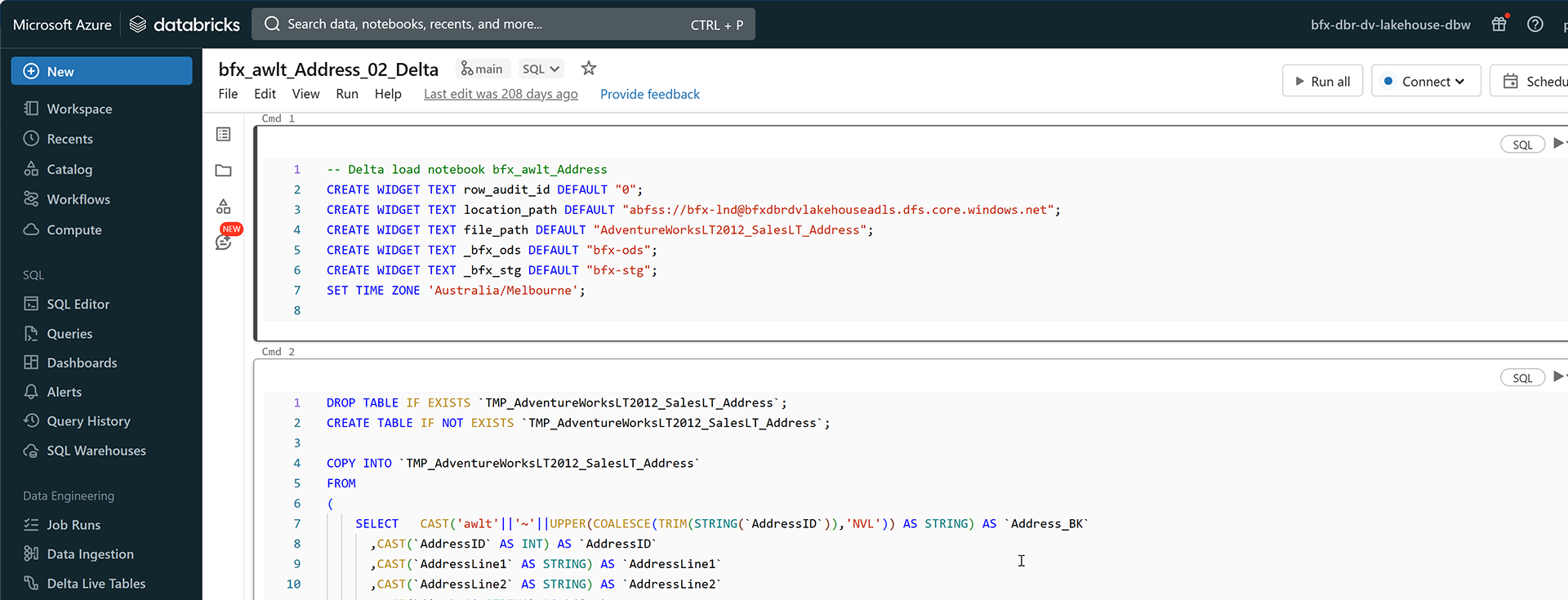
Conclusion
The synergy of Databricks and BimlFlex provides an enhanced approach to Azure Data Factory automation. From efficient data extraction to seamless staging and integration, users can optimize operations, reduce costs, and streamline the data transformation process. This integration truly represents the future of data analytics and cloud-based solutions.