Dev Diary - Integration with the BimlCatalog
September 15, 2021
Every data solution benefits from a robust control framework for data logistics. One that manages if, how and when individual data logistics processes should be executed. A control framework also provides essential information to complete the audit trail that tracks how data is processed through the system and is ultimately made available to users.
Working with Biml via either BimlExpress or BimlStudio provides the language, compiler, and development environment to create your own data solution frameworks from scratch, which means the control framework must be defined also.
BimlFlex has the advantage that that the output that is generated is already integrated with the proprietary control framework that is provided as part of the solution: the BimlCatalog. The BimlCatalog is the repository that collects runtime information and manages the registration of individual data logistics processes. It is used to control the execution and provides operational reporting on the overall loading process such as run times and success / failure rates.
The BimlCatalog is available freely and can be integrated with your own custom solution – for example using BimlExpress. However, when using BimlFlex the integration of the patterns with the BimlCatalog is already available out of the box. This is the topic of today’s post.
BimlCatalog integration for Mapping Data Flows
The BimlCatalog classifies data logistics as either an individual process or a batch. A batch is a functional unit of execution that calls one or more individual processes. Processes can either be run individually, or as part of the batch if one is defined. In Azure Data Factory, a batch is essentially an Execute Pipeline that calls other pipelines.
To inform the control framework of this, a flag that labels a process as a batch is passed to the stored procedure that is provided by the BimlCatalog. This procedure, the LogExecutionStart also accepts the execution GUID, the name of the process and the project it belongs to as input parameters.

The LogExecutionStart will run a series of evaluations to determine if a process is allowed to be run, and if so under what conditions. For example, an earlier failure may require a clean-up or it may be that the same process is already running. In this case, the control framework will wait and retry the start to allow the earlier process to complete gracefully. Another scenario is that already successfully completed processes that have been run as part of a batch may be skipped, because they already ran successfully but have to wait until the remaining processes in the batch are also completed without errors.
After all the processes are completed, a similar procedure (LogExecutionEnd) informs the framework that everything is OK.
A similar mechanism applies to each individual process, as is visible in the screenshot below.
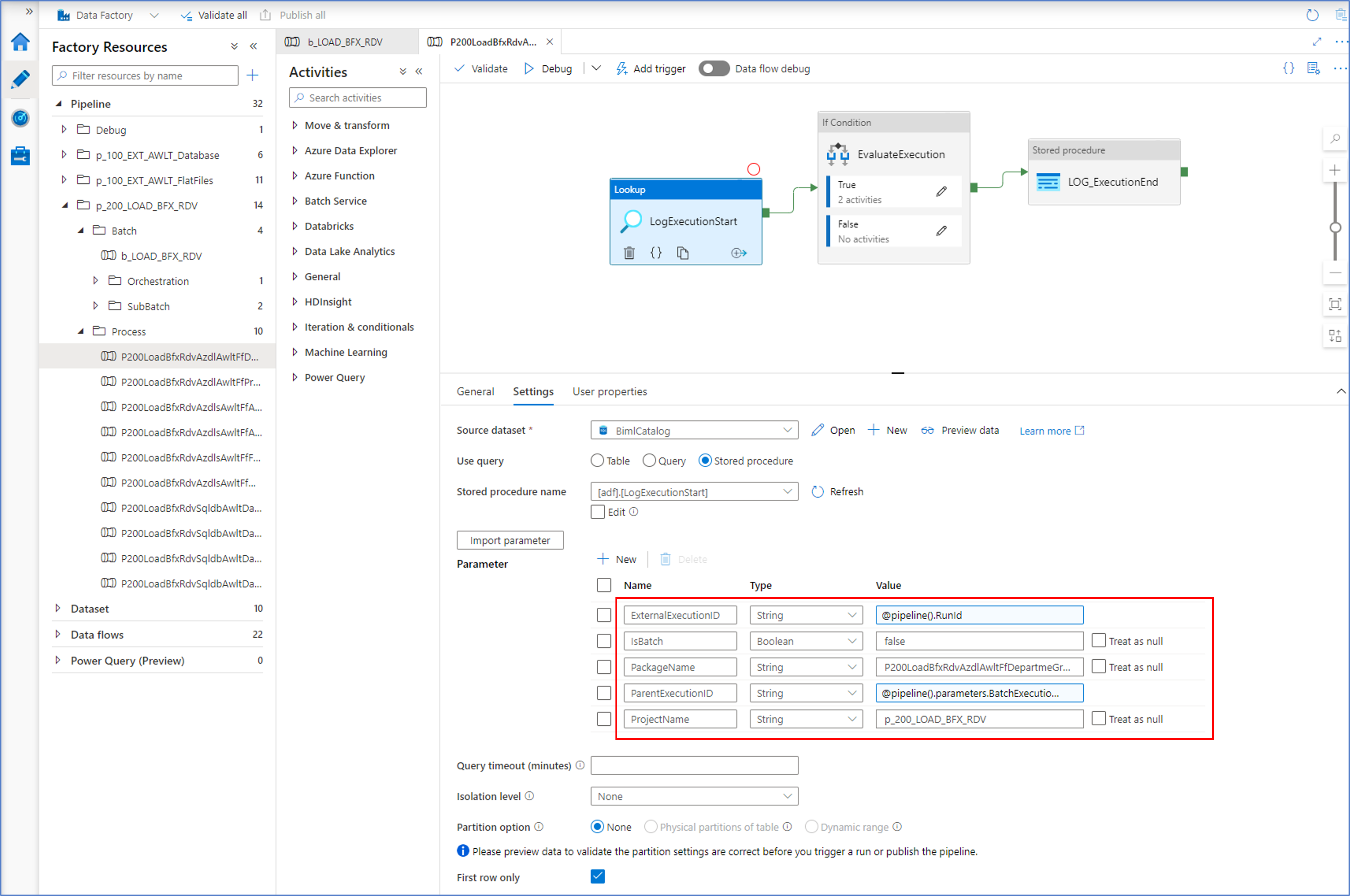
In this example, the IsBatch flag is set to 'false' as this is not a process that calls other processes. Similarly, a parent execution ID is provided - the runtime execution ID of the (batch) process that calls this one.
In case something goes wrong
So far, the focus of the control framework integration has been on asserting a process can start and under what conditions. However, it is important to make sure that any failures are handled and reported. This is implemented at the level of each individual process.
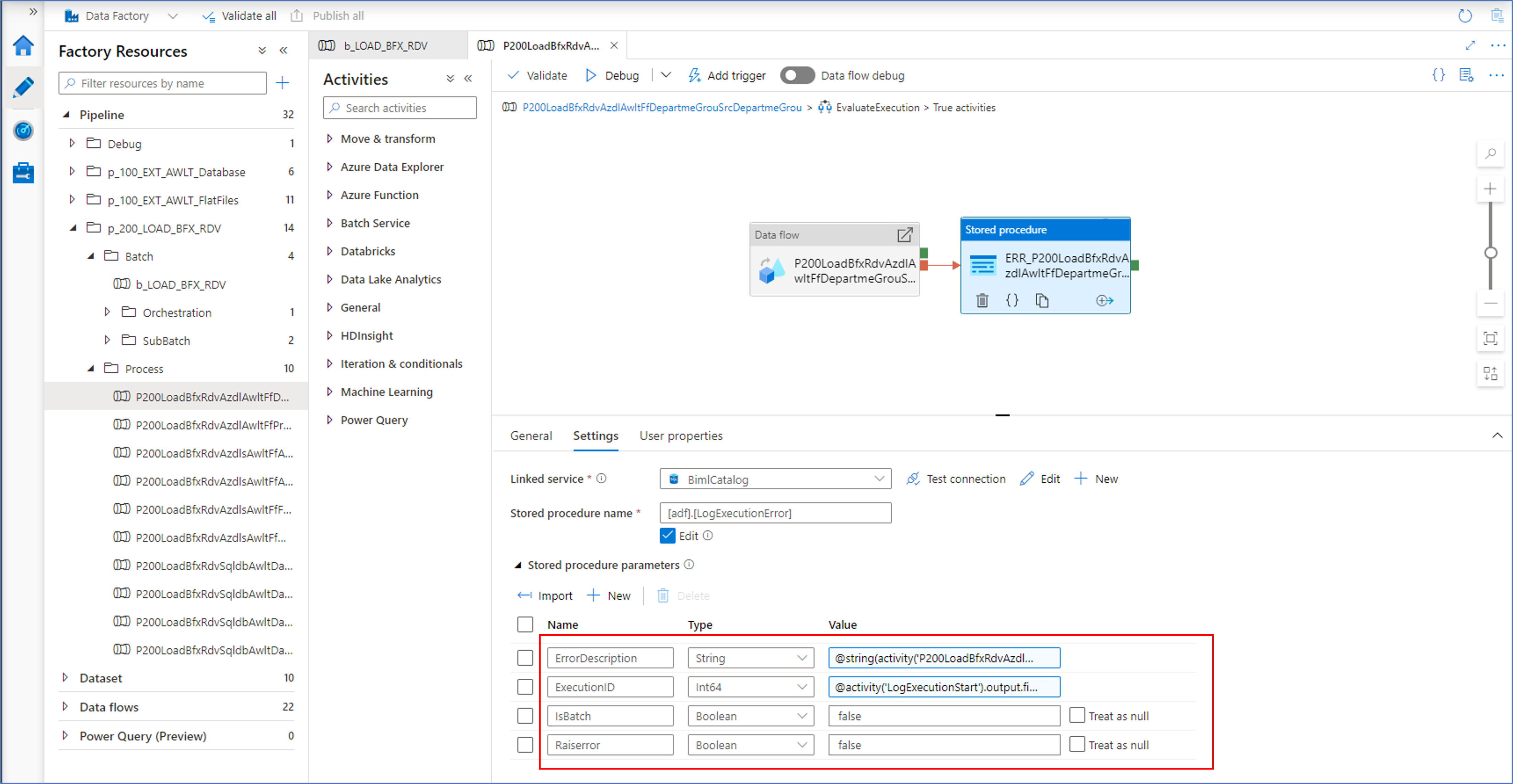
Each individual execute pipeline that calls a Mapping Data Flow will report any errors encountered by calling the LogExecutionError procedure. Within the BimlCatalog, this will also cause the parent batch to fail and inform subsequent processes in the same batch to gracefully abort. The batch will preserve the integrity of the data for all processes it encapsulates.